흔히 크롤링 할 때 파이썬을 많이 사용하는 것으로 알고있다.
하지만 글쓴이는 파이썬을 별로 좋아하지 않기 때문에 javascript를 이용하여 크롤링을 해보려고 한다.
1. 설치
혹시 node.js가 안깔려있다면 깔도록 하자.
다운로드 | Node.js
Node.js® is a JavaScript runtime built on Chrome's V8 JavaScript engine.
nodejs.org
2. init
crawling이라는 폴더를 만들고 나서 에디터로 작업창을 구성하자
터미널을 켜준뒤 다음 명령어를 실행하자.
| npm init (후에 명령어 끝날때까지 엔터) npm install puppeteer |
crawling 폴더 안에 app.js파일을 생성하자
여기까지 기본 준비 과정이 끝났다.
3. 테스트 코드
puppeteer공식 사이트에 있는 스크린샷 찍는 예제이다.

코드를 저장한 후에 터미널에서
| node app.js |
명령어를 실행하자.
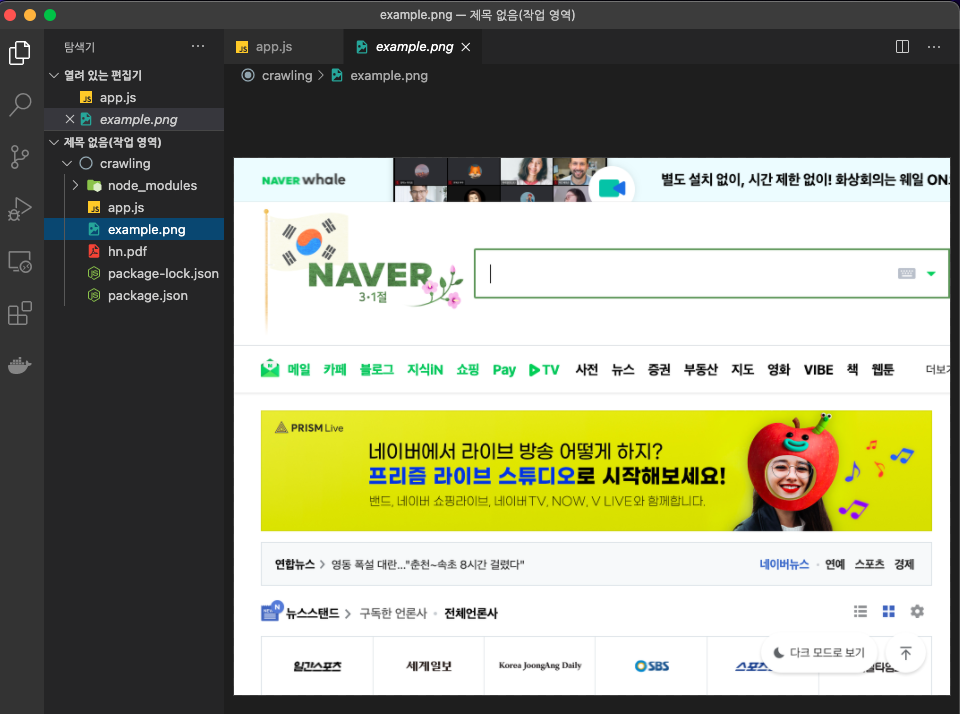
잠시 뒤 폴더를 보면 example.png라는 파일이 생기고 naver에 접속하지도 않았는데 naver배너의 사진이 떡하니 있는것을 볼 수 있다.
'Javascript' 카테고리의 다른 글
| Javascript Closure (0) | 2021.11.01 |
|---|---|
| [javascript] ?. 옵셔널 체이닝 연산자 (0) | 2021.08.27 |
| javascript 변수2 (var, let, const) (0) | 2021.04.22 |
| javascript 변수 (0) | 2021.04.01 |